Chapter 5 Tree
5.0.1 Tree Representation
Trees can be represented in multiple ways depending on the problem platform and constraints. Understanding these representations is crucial for interviews, as the same algorithm may need to be adapted to different input formats.
5.0.1.1 TreeNode Object Representation (Pointer-Based)
Most Common On: LeetCode, Interview Boards
The classic representation using node objects with pointers to children.
Characteristics:
- Navigation: Direct pointer access via
node.leftandnode.right - Memory: Each node stores explicit references to children
- Use Cases: Most tree algorithm problems, binary trees, BSTs
- Pros: Intuitive, matches tree mental model, easy to visualize
- Cons: Memory overhead from object headers and pointers
Example Problem: Maximum Depth of Binary Tree (LeetCode 104)
5.0.1.2 Array/Index-Based Representation
Most Common On: HackerRank, Competitive Programming
Represents the tree using parallel arrays where indices define parent-child relationships.
Format:
values[i]: Value stored in nodeileftChild[i]: Index of left child of nodei, or-1if nonerightChild[i]: Index of right child of nodei, or-1if none- Root is typically at index
0
Characteristics:
- Navigation: Array lookups via
leftChild[idx]andrightChild[idx] - Memory: More space-efficient, no object overhead
- Use Cases: Large trees, competitive programming, serialization
- Pros: Compact storage, cache-friendly, no pointer overhead
- Cons: Less intuitive, requires index bounds checking
Example Problem: Height of Binary Search Tree (HackerRank)
private static int calHeight(int idx, List<Integer> leftChild, List<Integer> rightChild) {
if (idx == -1) return 0;
return 1 + Math.max(
calHeight(leftChild.get(idx), leftChild, rightChild),
calHeight(rightChild.get(idx), leftChild, rightChild)
);
}Key Difference from TreeNode: The algorithm logic is identical (recursive DFS), but navigation changes from node.left to leftChild[idx].
5.0.1.3 Level-Order Array Representation (Heap-Style)
Most Common On: Array-based heap problems, some LeetCode inputs
Uses a single array where parent-child relationships are defined by index arithmetic.
Format (0-indexed):
- Root at index 0
- For node at index i:
- Left child at index 2*i + 1
- Right child at index 2*i + 2
- Parent at index (i - 1) / 2
- null nodes represented as special values (e.g., null, -1, Integer.MIN_VALUE)
Characteristics:
- Navigation: Computed indices via arithmetic
- Memory: Wastes space for sparse trees (unbalanced)
- Use Cases: Heaps, complete binary trees, certain tree serialization formats
- Pros: Simple parent-child formulas, no explicit links needed
- Cons: Inefficient for sparse/skewed trees
Example - Find Parent:
public TreeNode getParent(int[] tree, int childIndex) {
if (childIndex == 0) return null; // Root has no parent
int parentIndex = (childIndex - 1) / 2;
return tree[parentIndex] == null ? null : tree[parentIndex];
}Example Tree:
Tree Structure: Array Representation:
1 [1, 2, 3, 4, 5, null, 6]
/ \
2 3 Indices:
/ \ \ 0: 1 (root)
4 5 6 1: 2 (left of 0)
2: 3 (right of 0)
3: 4 (left of 1)
4: 5 (right of 1)
5: null (left of 2)
6: 6 (right of 2)5.0.1.4 Adjacency List Representation (Graph-Style)
Most Common On: N-ary trees, graph-based tree problems
Represents trees as a graph using adjacency lc-lists (edges from parent to children).
Format:
Map<Integer, List<Integer>> adjList = new HashMap<>();
// adjList.get(nodeValue) returns lc-list of childrenCharacteristics:
- Navigation: Loop through
adjList.get(node)to visit children - Memory: Flexible, efficient for n-ary trees
- Use Cases: N-ary trees, tree construction from edges, graph problems
- Pros: Handles variable number of children, natural for graph algorithms
- Cons: Requires additional data structure (HashMap), no guaranteed ordering
Example - N-ary Tree DFS:
5.0.1.5 Parent Array Representation
Most Common On: Union-Find tree problems, parent pointer tracking
Represents trees by storing each node’s parent (reverse of typical representation).
Format:
parent[i]: Index of parent of nodei, or-1/iif root
Characteristics:
- Navigation: Bottom-up traversal (child to parent)
- Memory: Single array
- Use Cases: Union-Find, LCA (Lowest Common Ancestor), path compression
- Pros: Very space-efficient, enables union-find operations
- Cons: Only supports upward traversal
Example - Find Root:
5.0.1.6 Comparison Table
| Representation | Space | Navigation | Best For | Platforms |
|---|---|---|---|---|
| TreeNode Objects | O(n) + overhead | Direct pointers | Binary trees, BSTs | LeetCode, Interviews |
| Index Arrays | O(n) | Array lookups | Large trees, serialization | HackerRank, Competitive |
| Level-Order Array | O(n) to O(2^h) | Arithmetic | Complete trees, heaps | Heap problems |
| Adjacency List | O(n + edges) | Map lookups | N-ary trees, graphs | Graph-based problems |
| Parent Array | O(n) | Bottom-up only | Union-Find, LCA | DSU problems |
5.0.1.7 Traversal Strategy
Key Insight: The representation is an implementation detail. The core algorithm remains the same across representations.
Example - Same DFS Algorithm, Different Representations:
// TreeNode representation
int maxDepth(TreeNode root) {
if (root == null) return 0;
return 1 + Math.max(maxDepth(root.left), maxDepth(root.right));
}
// Index-based representation
int maxDepth(int idx, List<Integer> left, List<Integer> right) {
if (idx == -1) return 0;
return 1 + Math.max(maxDepth(left.get(idx), left, right),
maxDepth(right.get(idx), left, right));
}Notice: Only the navigation changed (root.left → left.get(idx)). The recursive structure is identical.
Interview Tips:
- Clarify input format before coding
- Translate the representation mentally to your preferred style
- Write helper methods for navigation if the format is complex
- Test edge cases specific to the representation (e.g.,
-1for null in arrays)
5.0.2 Breadth First Traversal
The algorithm starts at the tree root, and explores all of the neighbor nodes at the present depth prior to moving on to the nodes at the next depth level.
5.0.2.1 Implementation Steps
bfs 1.3.2
5.0.2.3 Complexity Analysis
- Time Complexity: Breadth-first search visits every vertex once and checks every edge in the graph once. Therefore, the runtime complexity is \(O(|V| + |E|)\). In simplicity, O(n) since \(|V| = n\)
- Auxiliary Space: In Breadth First traversal, visited node in different level is stored in a queue one by one. Extra Space required is O(w) where w is maximum width of a level in binary tree.
5.0.3 Depth First Traversal
The algorithm starts at the root node and explores as far as possible along each branch.
5.0.3.1 Implementation Steps
dfs 1.3.1
5.0.3.2 Type of Depth First Traversal
- Depth First InOrder Traversal
- Depth First PreOrder Traversal
- Depth First PostOrder Traversal
5.0.3.3 Complexity Analysis
- Time Complexity: Depth-first search visits every vertex once and checks every edge in the graph once. Therefore, the runtime complexity is \(O(|V| + |E|)\). In simplicity, O(n) since \(|V| = n\)
- Auxiliary Space: In Depth First Traversals, stack (or function call stack) stores all ancestors of a node. Extra Space required is O(h) where h is maximum height of binary tree.
5.0.4 Pre-Order Traversal
Pre-order traversal visits nodes in the order: Root → Left → Right.
5.0.4.1 Characteristics
- Visit order: Process the current node first, then recursively traverse left subtree, then right subtree
- Use cases:
- Creating a copy of the tree
- Prefix expression evaluation
- Tree serialization (encoding tree structure)
- Directory listing (parent before children)
5.0.4.3 Typical Implementation - Java (Iterative)
public void preOrderTraversal(TreeNode root) {
if (root == null) return;
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.pop();
System.out.println(node.val);
// Push right first so left is processed first
if (node.right != null) stack.push(node.right);
if (node.left != null) stack.push(node.left);
}
}5.0.5 In-Order Traversal
In-order traversal visits nodes in the order: Left → Root → Right.
5.0.5.1 Characteristics
- Visit order: Recursively traverse left subtree, process current node, then recursively traverse right subtree
- Use cases:
- Binary Search Tree (BST) traversal produces sorted output
- Expression tree evaluation (infix notation)
- Validating BST properties
- Finding kth smallest element in BST
5.0.5.3 Typical Implementation - Java (Iterative)
public void inOrderTraversal(TreeNode root) {
Stack<TreeNode> stack = new Stack<>();
TreeNode current = root;
while (current != null || !stack.isEmpty()) {
// Reach the leftmost node
while (current != null) {
stack.push(current);
current = current.left;
}
// Process node
current = stack.pop();
System.out.println(current.val);
// Visit right subtree
current = current.right;
}
}5.0.6 Post-Order Traversal
Post-order traversal visits nodes in the order: Left → Right → Root.
5.0.6.1 Characteristics
- Visit order: Recursively traverse left subtree, then right subtree, then process current node
- Use cases:
- Deleting or freeing nodes (children before parent)
- Postfix expression evaluation
- Calculating directory sizes (children before parent)
- Bottom-up computations (height, tree diameter)
5.0.6.3 Typical Implementation - Java (Iterative)
public void postOrderTraversal(TreeNode root) {
if (root == null) return;
Stack<TreeNode> stack1 = new Stack<>();
Stack<TreeNode> stack2 = new Stack<>();
stack1.push(root);
// Push nodes to stack2 in reverse post-order
while (!stack1.isEmpty()) {
TreeNode node = stack1.pop();
stack2.push(node);
if (node.left != null) stack1.push(node.left);
if (node.right != null) stack1.push(node.right);
}
// Pop from stack2 for correct post-order
while (!stack2.isEmpty()) {
System.out.println(stack2.pop().val);
}
}5.0.7 Selection Strategy
- Extra Space can be one factor
- Depth First Traversals are typically recursive and recursive code requires function call overheads.
- The most important points is, BFS starts visiting nodes from root while DFS starts visiting nodes from leaves. So if our problem is to search something that is more likely to closer to root, we would prefer BFS. And if the target node is close to a leaf, we would prefer DFS
- Maximum Width of a Binary Tree at depth (or height) h can be 2h where h starts from 0. So the maximum number of nodes can be at the last level. And worst case occurs when Binary Tree is a perfect Binary Tree with numbers of node
- It is evident from above points that extra space required for Level order traversal is likely to be more when tree is more balanced and extra space for Depth First Traversal is likely to be more when tree is less balanced.
5.0.8 Binary Search Tree
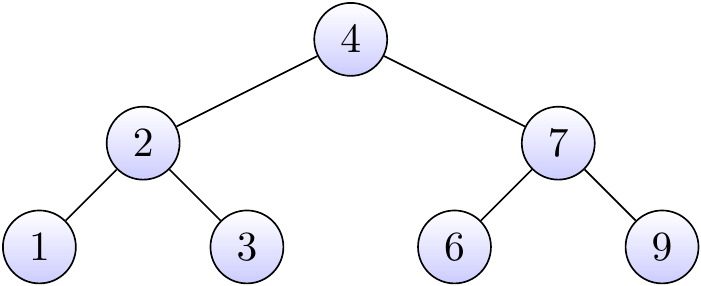
Figure 5.1: Some caption.
A BST is a binary tree where nodes are ordered in the following way:
- each node contains one key (also known as data)
- the keys in the left subtree are less then the key in its parent node
- the keys in the right subtree are greater the key in its parent node
- duplicate keys are not allowed.
5.0.8.1 Implementation Steps
bst 1.3.11
5.0.8.2 Complexity Analysis
The particular kind of binary tree is optimized in a way that only a PARTIAL nodes along a path will be visited during search, the general time complexity is reduced to O(h) where h = log(n).
Since a binary search tree with n nodes has a minimum of O(log(n)) levels, it takes at least O(log(n)) comparisons to find a particular node. However, in the edge cases where tree is in a lc-list form, the worst time complexity is O(n)